chapter 10-1 탐색적 데이터 분석
탐색적데이터분석(EDA)
가공하지 않은 데이터를 그대로 탐색/분석하는 기법
EDA의 목적
데이터의 형태와 척도가 분석에 알맞게 되어 있는지 확인
데이터의 평균, 분산, 분포, 패턴 등을 확인해 데이터의 특성 파악
데이터의 결측값, 이상치 파악 및 보완 변수 간의 관계성 파악
분석 목적과 방향성 점검 및 보정
데이터 분석 실습
head() : 데이터를 확인할 수 있는 메서드
info() : 각 칼럼의 데이터 타입 및 결측치 개수를 알 수 있다.
describe() : 각 칼럼의 평균, 표준편차, 최대/최소 등을 알 수 있다.
skew() : 각 칼럼의 왜도를 확인할 수 있다.
왜도
데이터 분포의 좌우 비대칭도를 표현하는 척도이며 데이터 분포가 좌우 대칭일수록 왜도값은 감소, 편향되어 있을수록 왜도값은 증가한다. 또한 분포가 왼쪽으로 치우쳐 오른쪽으로 긴 꼬리를 가지면 양수, 반대의 경우 음수가 된다.


kurtosis(): 각 칼럼의 첨도를 확인할 수 있다.
첨도
첨도는 데이터 분포가 정규분포에 비해 얼마나 뾰족하고 완만한지의 정도를 나타내는 척도이며 중심에 얼마나 쏠려 있는가를 나타낸다.
3을 기준으로 값이 클수록 뾰족한 양의 첨도이며 작을수록 음의 첨도이지만 -3을 적용해 음수/양수로 구분하기도 한다

seaborn() : 패키지의 distplot 함수를 사용해 칼럼의 분포를 시각화 할 수 있다.
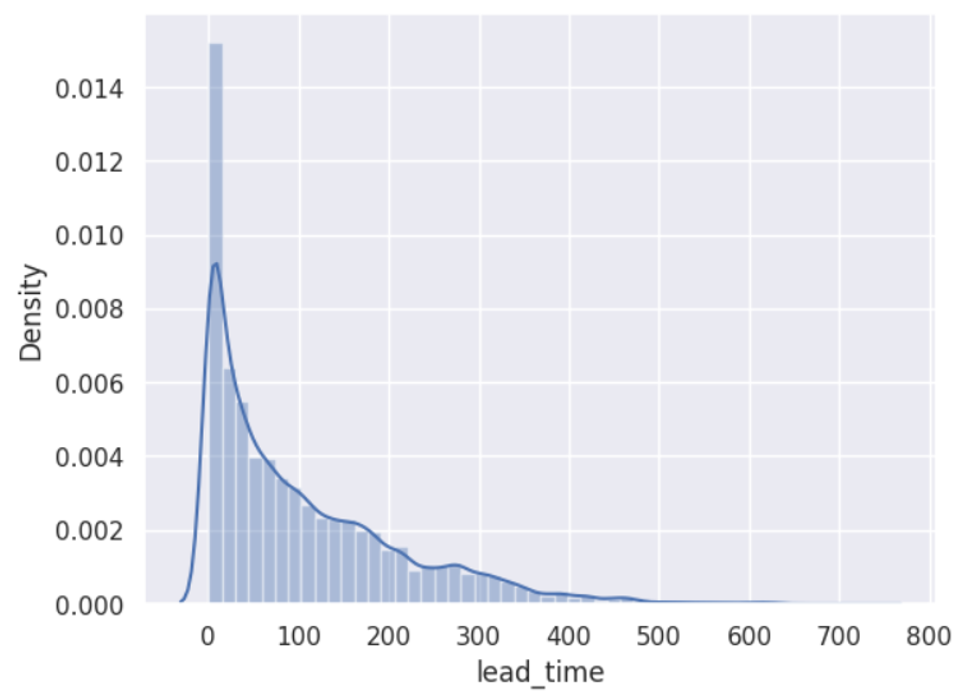
violinplot() : 호텔 구분에 따른 lead_time 칼럼 분포를 시각화할 수 있다.
srtipplot() : 호텔별 lead_time 칼럼의 각 관측치의 위치를 표현해준다.

chapter 10-2 공분산과 상관성 분석
공분산
두 변수 간의 분산의 관계, 즉 서로 공유하는 분산을 나타낸다. 각 샘플별로 두 변수에 대한 분산을 구해(해당 값 - 평균값) 서로 곱한 값을 모든 샘플에 대해 더하고 다시 샘플 수로 나눠 구할 수 있다. 해당 값이 0이면 두 변수는 상관관계가 없는 것이며 해당 값이 양수이면 양의 상관관계, 음수이면 음의 상관관계를 가진다는 것을 알 수 있다.
피어슨 상관계수
두 변수의 공분산을 두 변수 각각의 전체 분산으로 나눠 구한다. 따라서 그 값은 -1과 1 사이의 값을 가진다(양 끝 값 포함).
일반적으로 상관계수의 절댓값이 0.4 이상이면 어느 정도 상관관계가 있다고 해석하고 0.7 이상이면 강한 상관관계가 있다고 해석한다. 상관계수 값에 따른 상관관계 분포는 다음과 같다.

이때 산점도의 기울기 값은 상관계수와 관계가 없다. 상관계수가 높다는 것은 변수 X1이 움직일 때 변수 X2가 많이 움직이는 것이 아니라, 변수 X1이 변수 X2에 대해 예상할 수 있는 정확도(설명력)가 높다는 것이다.
또한 상관분석은 두 변수의 선형적 관계만을 측정하기 때문에 두 변수의 분포가 2차함수 형태를 띌 경우 상관관계가 매우 낮게 나온다.
ㄷ따라서 상관분석을 할때 산점도 그래프를 별도로 그려 보는 것이 좋다.
피어슨 상관관계 분석 방법
Pearson correlation coefficient : 간격/비율 - 간격/비율
Spearman’s rank correlation coefficient : 서열 - 서열
Point-biserial correlation coefficient : 간격/비율 - 명목(2분 변수)
Phi coefficient : 명목(2분 변수) - 명목(2분 변수)
Cramer’s coefficient : 명목 - 명목 (2 X 2 이상)
등간척도 - IQ, 온도 등 동일한 간격으로 서열을 매긴 척도
비율척도 - 무게, 길이 등 절대영점이 존재하며 ‘10m는 5m의 두배이다’ 같은 절대적 크기 비교가 가능한 척도
명목척도 - 범주화하여 나타내는 척도. 숫자나 기호를 부여해 사용하기도 함
서열척도 - 생활 수준 등 서열을 매길 수 있으나 그 간격은 동일하지 않은 척도
공분산과 상관성 분석 실습

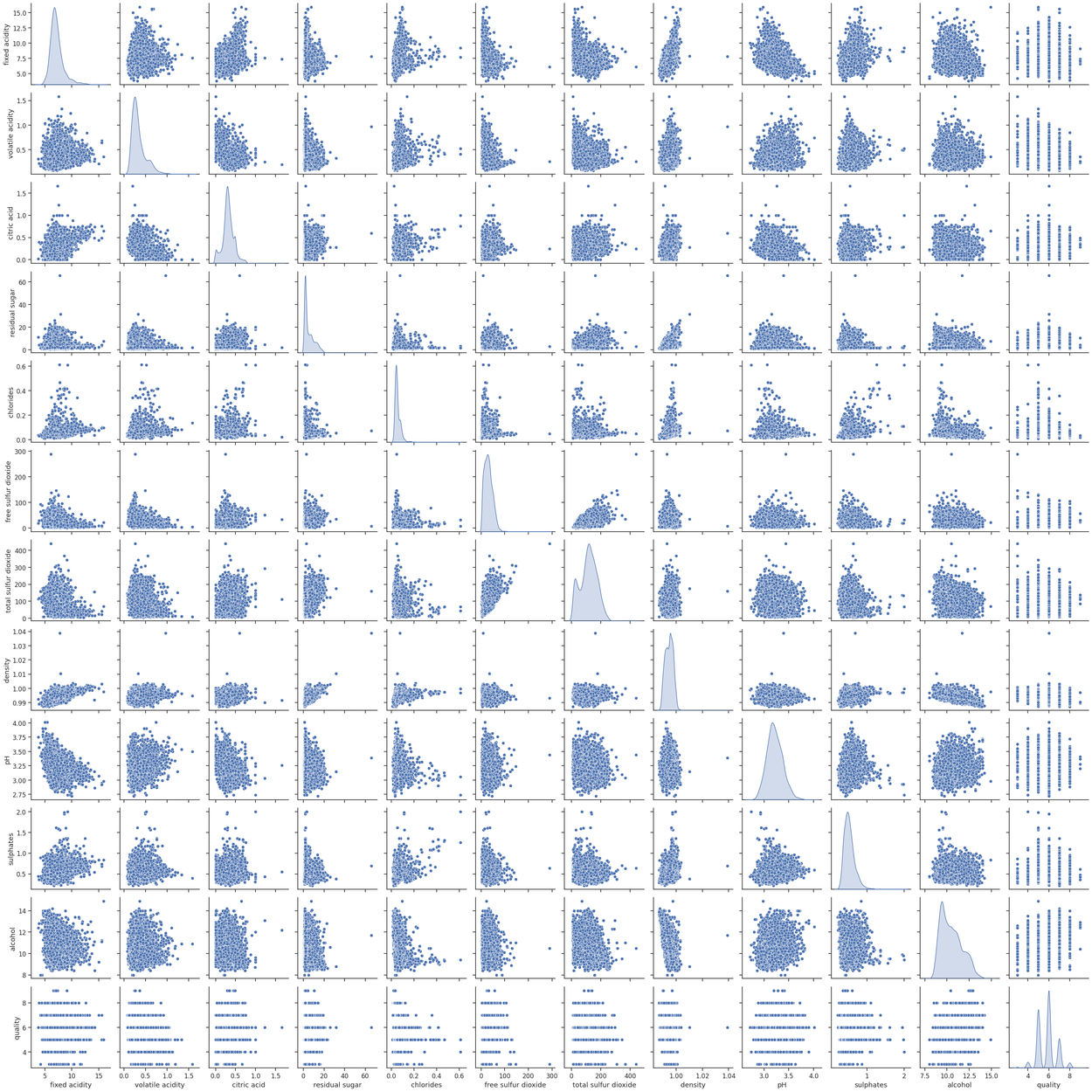
cov() 함수를 통해 공분산을 구해 표로 정리해 나타낸다 .
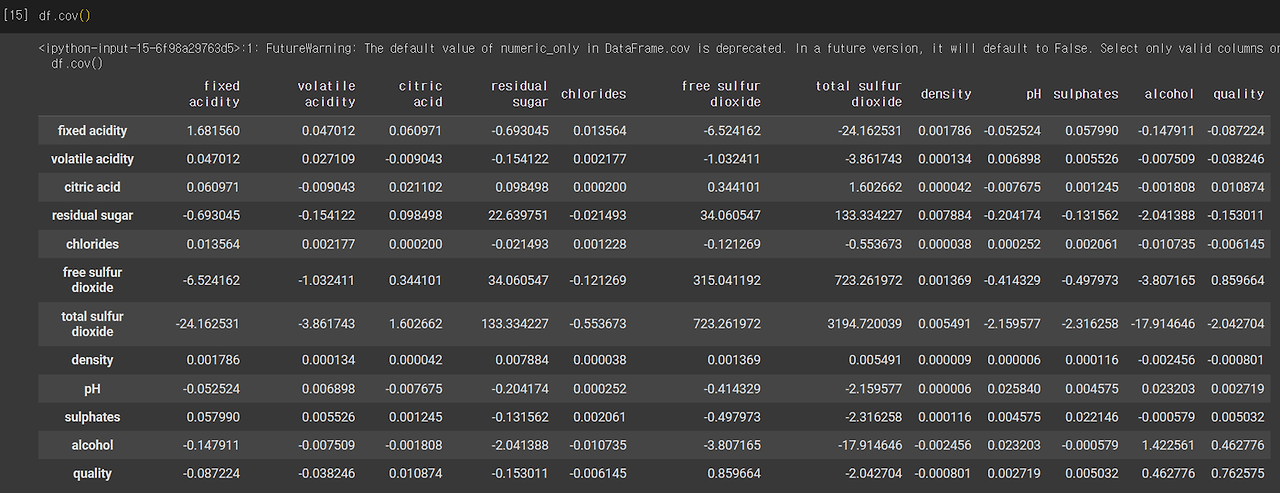
상관분석은 corr( ) 함수로 확인할 수 있다. method 매개변수(디폴트값 pearson)로 상관계수 산출 방법을 지정할 수 있다.

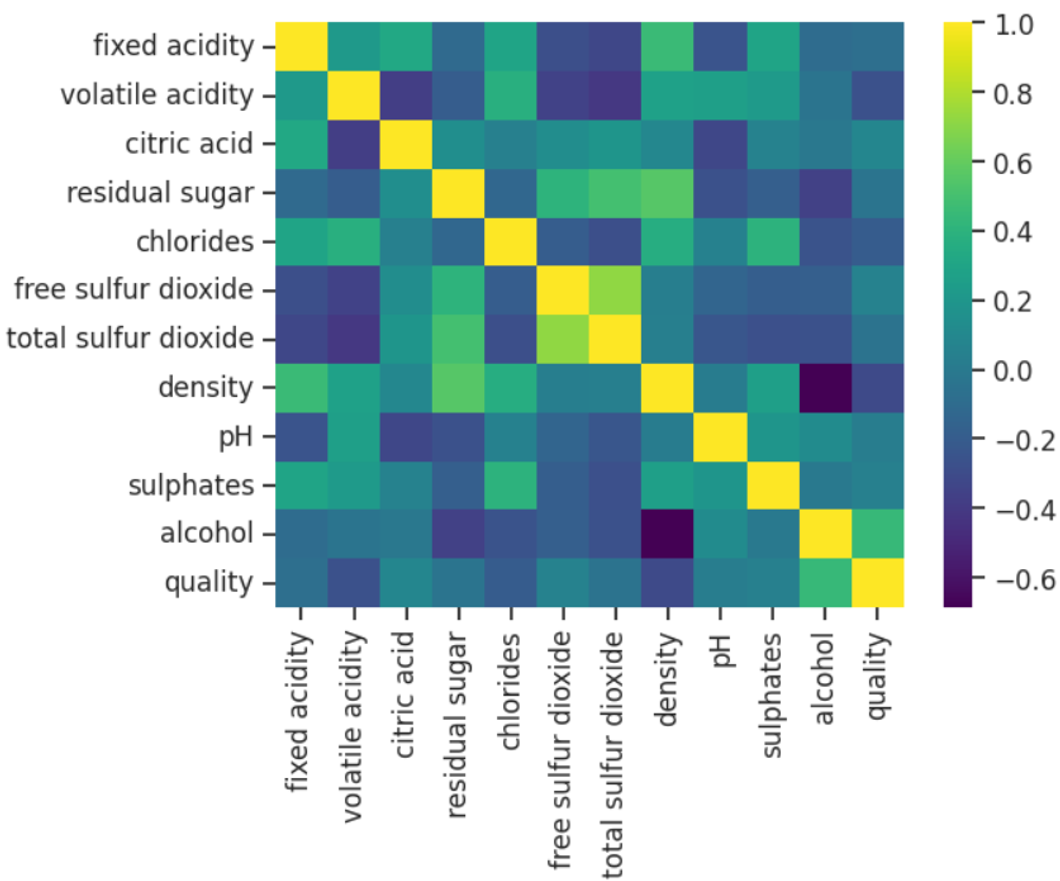

clustermap() : 상관계수를 표시해 줄 뿐만 아니라 상관성이 강한 변수끼리 묶어서 표현해주기도 한다.
chapter 10-3 시간 시각화
시간시각화는 선 그래프 형태인 연속형과 막대그래프 형태인 분절형이 있다.
시간 간격의 밀도가 높을 때(초 단위 데이터처럼) 주로 선그래프를 사용한다. 하지만 데이터의 양이 너무 많거나 변동이 심하면 패턴을 파악하기 난해하므로 이때는 추세선을 삽입하기도 한다.
추세선
들쭉날쭉한 데이터 흐름을 안정된 선으로 표현할 수 있으며 추세선을 그리는 가장 일반적인 방법으로는 이동평균 방법이 있다.
이동평균
만약 2 → 5 → 3 → 7 → 4 의 값을 가지는 데이터가 있다면 이를
(2, 5, 3의 평균) → (5, 3, 7의 평균) → (3, 7, 4의 평균)으로 나타내는 것이다.
시간의 밀도가 낮을 때 막대그래프, 누적 막대그래프가 주로 사용되며 값들의 상대적 차이를 나타낼 때 유용하다.
누적 막대그래프
시점별로 여러개의 세부 항목이 존재할 때 사용할 수 있다. 각 항목의 전체 합 또한 한번에 나타낼 수도 있고 전체에 대한 각 항목의 비율을 서로 비교할 수도 있어 유용하게 사용된다.
시간 시각화 실습
groupby() : 일별 매출액을 구할 수 있다.
rolling() : 함수를 사용해 30일 이동평균 칼럼을 만들고, 시각화를 진행
이동평균선을 통해 5월부터 매출이 감소, 8월에 다시 증가하는 것을 확인할 수 있다.

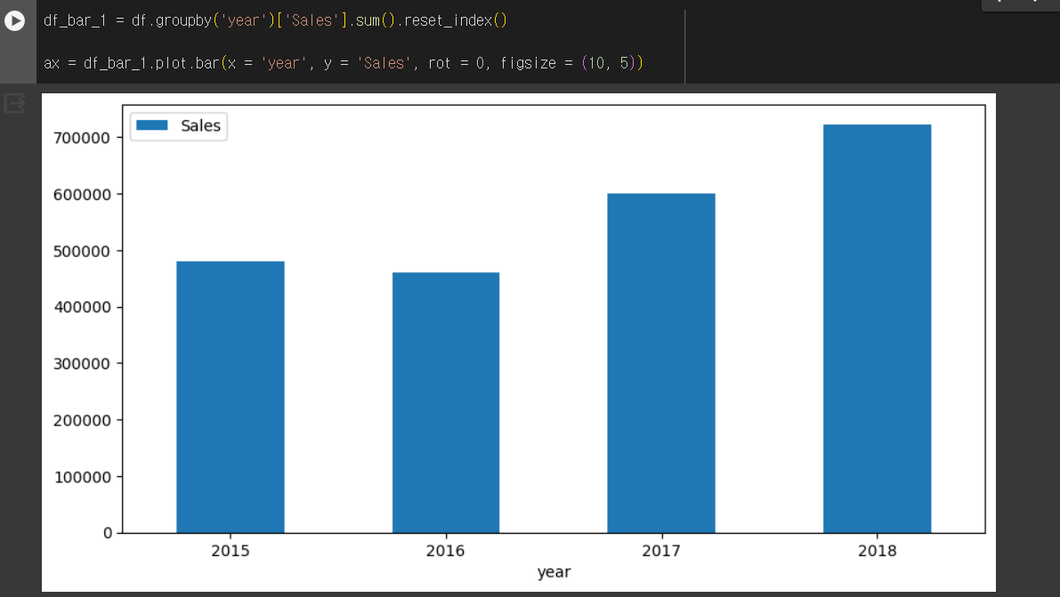

Q. 이동평균을 하는 이유?
데이터의 변동을 완화: 시계열 데이터에는 불규칙한 요인이 있어서 단기적으로 데이터가 변동하는 경우가 많습니다. 이동평균은 이러한 불규칙한 요인들을 완화시켜서 추세를 보다 명확하게 파악할 수 있도록 도와줍니다.
시간 지연 감소: 이동평균은 데이터의 시간 지연을 줄여줍니다. 특히 주가 데이터에서 사용될 때, 짧은 기간의 이동평균은 주가의 단기적인 움직임을 보다 빨리 반영할 수 있습니다.
신호 생성: 이동평균은 신호를 생성하는데 사용될 수 있습니다. 예를 들어, 이동평균이 상승 추세를 보이는 동안 주가가 이동평균을 상향 돌파하면 매수 신호로 간주될 수 있습니다.
chapter 10-4 비교 시각화
그룹과 비교 요소가 많을 때 그룹별 차이를 효과적으로 나타내기 위해서는 ‘히트맵 차트’를 이용한다.
차트의 행/열/색상을 각각 다른 변수로 설정하여 세 변수간의 관계를 살필 수도 있고 차트의 열을 시간 흐름으로 설정하여 시간에 따른 변화를 파악할 수도 있다.
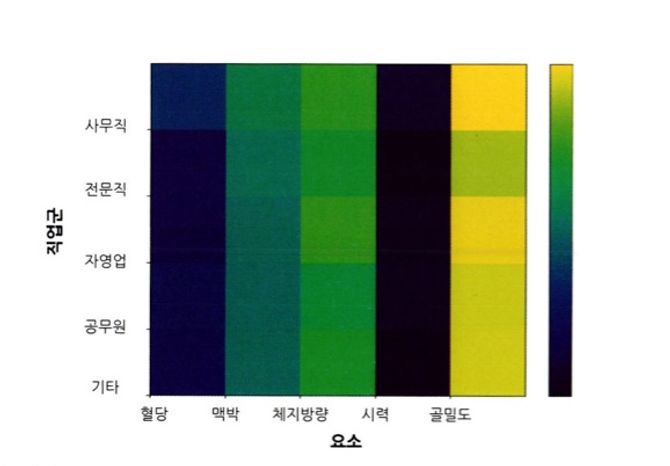
하나의 변수(그룹) X N개의 각 변수에 해당하는 값들

하나의 변수(그룹) X 하나의 변수(그룹/수준) X 하나의 변수(수준)
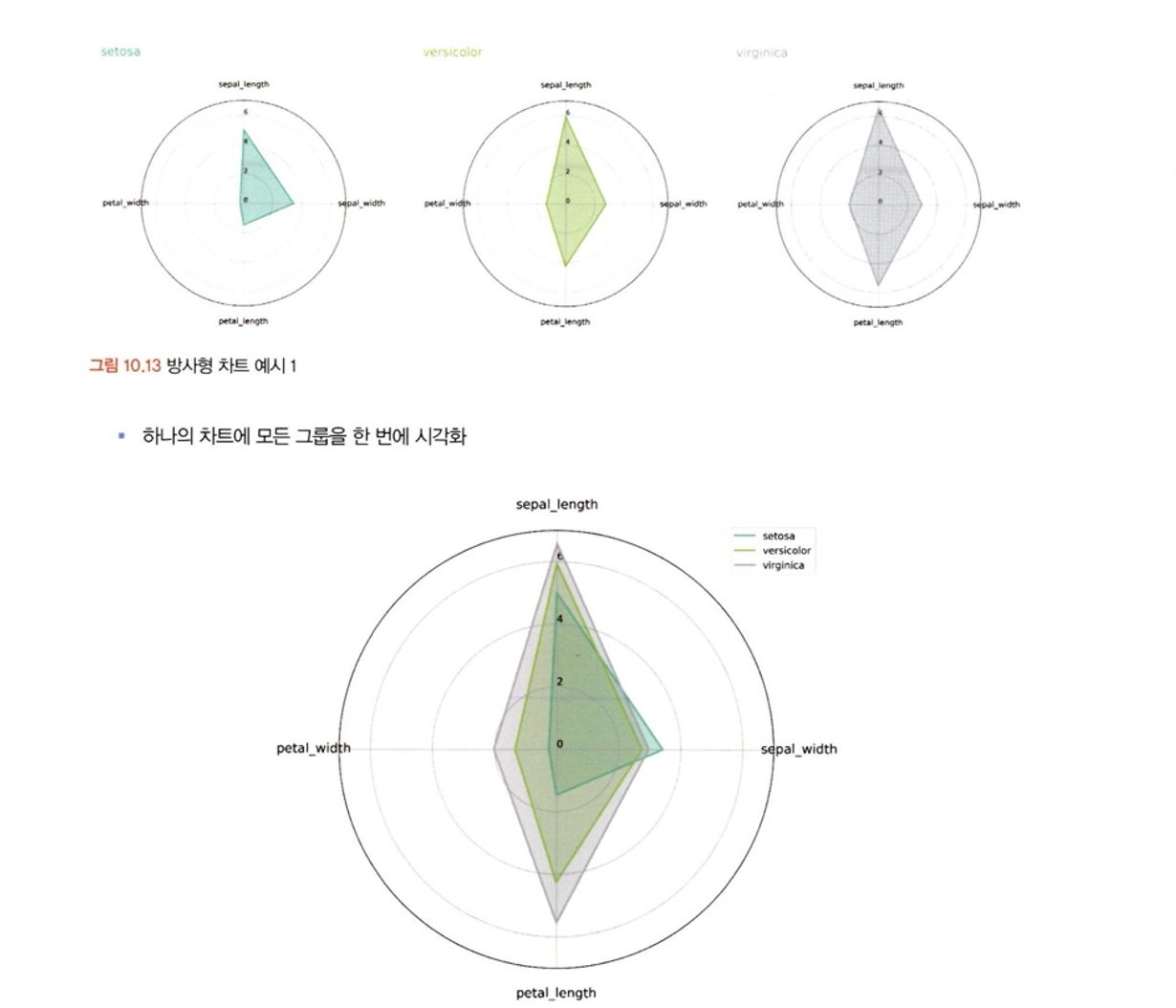
마지막으로 평행 좌표 그래프를 통해서도 비교 시각화가 가능하다. 변수별로 값들을 특정 범위로 변환한다면 더욱 효과적으로 시각화 할 수 있다.
chapter 10 - 5 분포 시각화
분포 시각화
데이터가 연속형 등의 양적 척도인지, 명목형 등의 질적 척도인지에 따라 구분하여 그린다.
<양적척도>
양적 척도의 경우 막대/선그래프, 혹은 히스토그램으로 나타낼 수 있다. 히스토그램은 구간을 쪼게 동일한 면적의 막대그래프를 이어 그린 그래프이며 처음에는 많은 구간으로 나누고 시각적인 정보의 손실이 커지기 전까지 구간의 개수를 줄여나가면서 그린다.
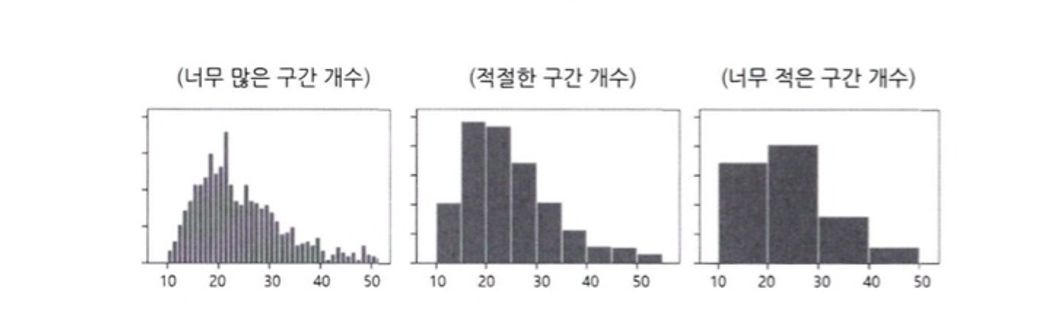
<질적척도>
변수의 구성이 단순한 경우에는 파이차트 혹은 도넛차트를 사용한다. 이들은 구성 요소들의 분포 정도를 면적(혹은 각도)으로 표시한다. 비율을 수치로 같이 입력해 주는 것이 좋다.
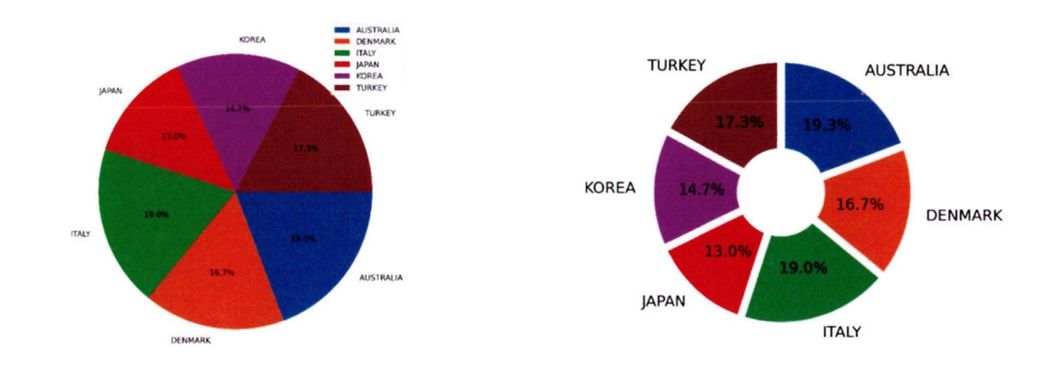
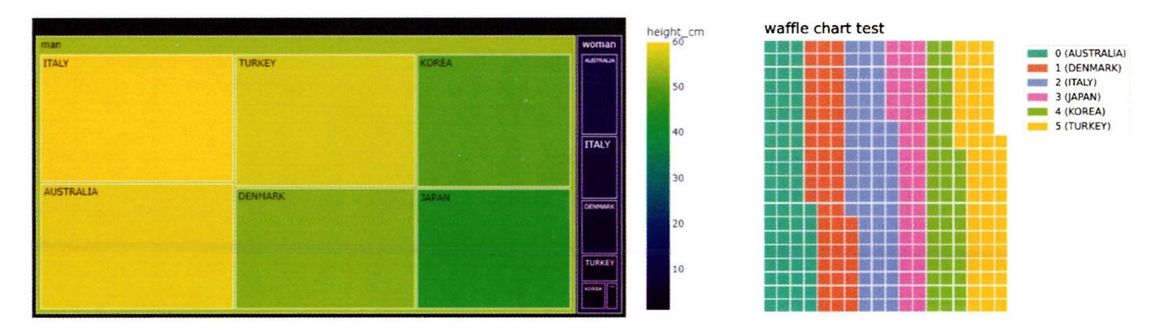
질적 척도에서 구성 요소가 복잡한 경우에는 트리맵 차트 혹은 와플 차트를 이용한다.
트리맵 차트
트리맵 차트에서는 하나의 큰 사각형 속에 비율에 따라 구성 요소들이 작은 사각형으로 쪼게져 들어가는데, 구성 요소 안에서도 분류를 나누어 더 작은 사각형으로 위계구조를 나타낼 수 있다(의류 매장에서 바지 품목 안에서 반바지와 긴바지로 한번더 나눌 수 있음).
와플차트
와플차트는 일정한 조각들로 분포를 표현하는데 위계구조를 표현하지는 못한다.
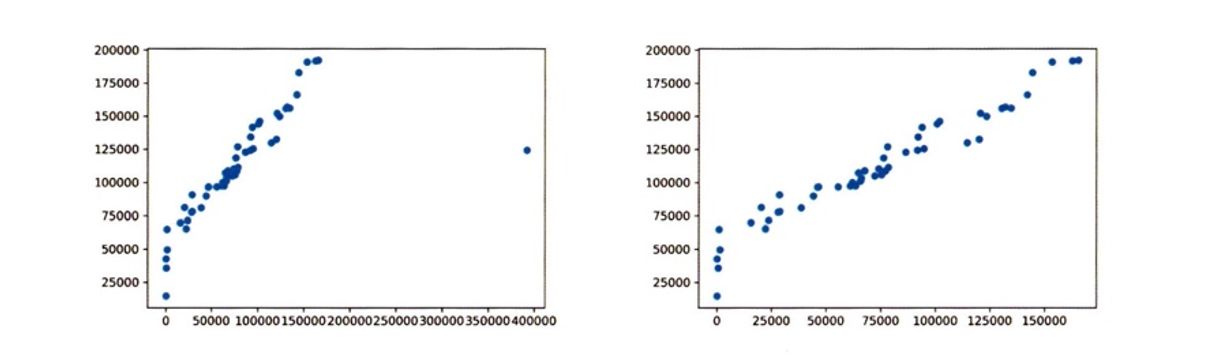
chapter 10 - 6 관계 시각화
산점도를 이용해 두 변수 간의 관계를 나타낼떄, 극단치가 있다면 이를 제거하고 그래프를 그리는 것이 좋다.
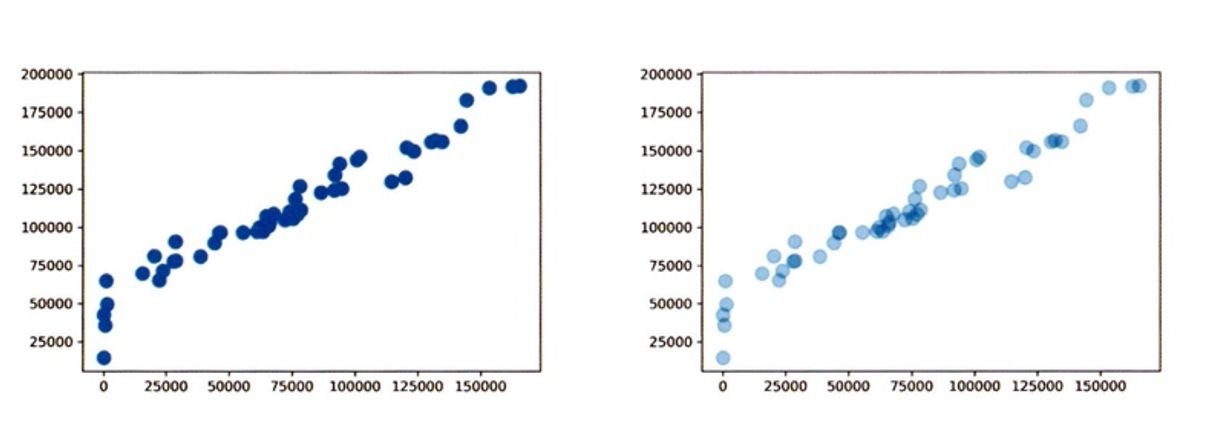
또한 산점도에서 데이터가 너무 많아 점끼리 겹쳐 정보를 확인하기 힘들 때 점들에 투명도를 주어 밀도를 함께 확인할 수 있다.
버블 차트
버블 차트에서는 세 변수(4개까지 가능하기는 하다) 간 상관관계를 표현할 수 있다. 버블의 크기(지름이 아닌 면적으로 반영한다)로 한 가지 요소를 추가로 표현하기 때문에 샘플이 너무 많을 때는 효과가 떨어진다.

chapter 10 - 7 공간시각화
위도와 경도 데이터를 지도에 표시하여 나타낼 수 있다(구글의 지오맵의 경우 지명만으로도 가능하다). 또한 인구 밀도 등의 집계 데이터도 지도 위에 표시해 유용하게 사용할 수 있다. 게다가 공간 시각화는 지도를 확대하거나 위치를 옮기는 등의 행동도 가능하다. 대표적인 공간시각화 기법은 다음과 같다.

- 도트맵 : 특정 위치에 작은 점을 찍는 기법이며 데이터의 개요를 파악하기에 용이하지만 정확한 값을 나타낼 수는 없다는 단점이 있다
- 버블맵 : 도트맵에서 원의 크기로 데이터 값을 표시하는 기법이다.
- 코로폴리스맵 : 색상의 음영으로 구역의 데이터 크기를 나타내는 기법이다. 음영 뿐만 아니라 여러 색을 혼합할 수도 있고 투명도, 명도, 채도 등으로 다양하게 표현할 수 있다.
- 커넥션맵 : 링크맵이라고도 하며 지도에 찍힌 점들을 직선 혹은 곡선으로 연결하는 기법이다. 여러 점을 한 선으로 연결해 경로를 표시할 수도
공간 시각화 실습
필요한 패키지를 임포트하고 파일을 업로드했다. geo 변수에는 서울 각 구의 경계를 표현해 줄 수 있는 파일을 업로드했다.

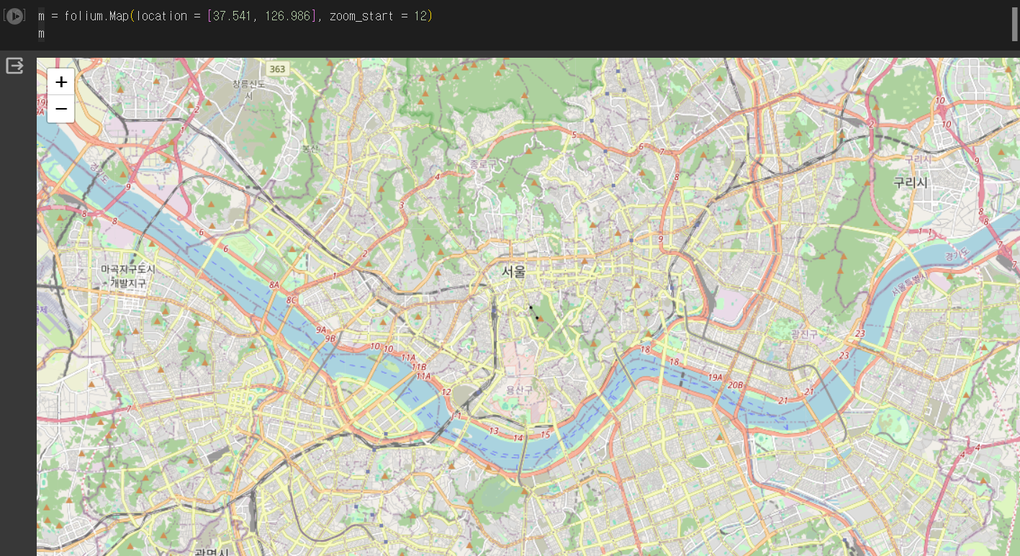
기본적으로 지도를 시각화하는 방법이다. tiles 매개변수로 지도의 형태를 다양하게 바꿀 수 있다.
CircleMarker( ) 함수로 지도의 원하는 위치에 원형 공간을 표시할 수 있고, Marker( ) 함수로 원하는 위치에 포인트 그림을 삽입할 수 있다.


chapter 10 - 8 박스플롯
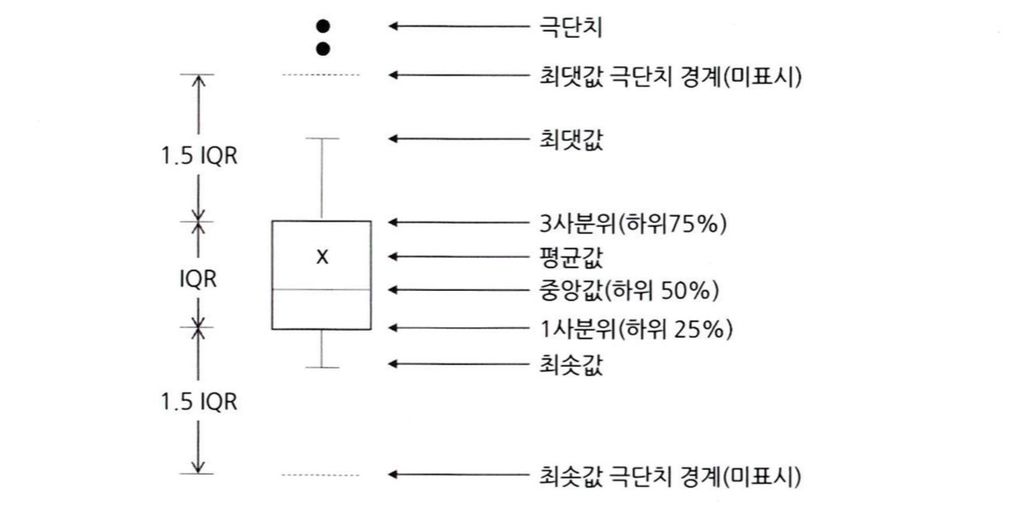
박스 플롯은 하나의 그림으로 양적 척도 데이터의 분포, 편향성, 평균, 중앙값 등을 모두 확인할 수 있는 구조를 지닌다

박스 플롯에서 나타내는 수치는 다음과 같다
- 최솟값 : 제1사분위에서 1.5 IQR을 뺀 위치까지의 최솟값
- 제1사분위 : 25%의 위치
- 제2사분위 : 50%의 위치(중앙값)
- 제3사분위 : 75%의 위치
- 최댓값 : 제3사분위에서 1.5 IQR을 더한 위치까지의
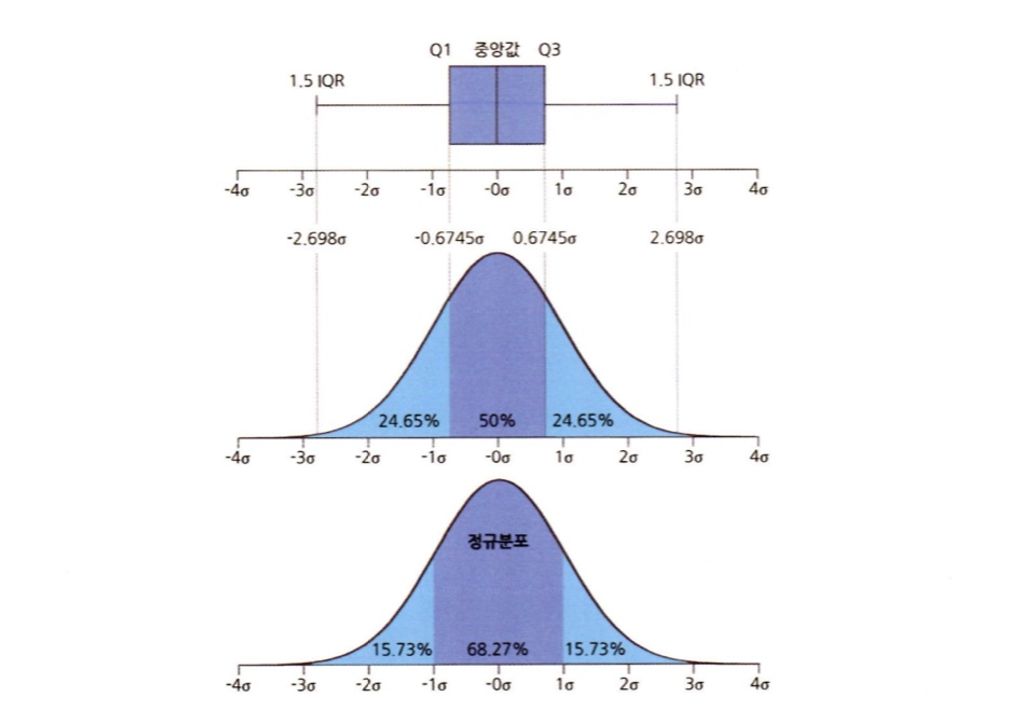
박스 플롯의 데이터 분포와 정규분포를 비교해 보면 박스 플롯의 박스 부분은 정규분포의 평균을 중심으로 좌우 1표준편차 안에 측정된 관측치 양과 비슷하고 양쪽 수염의 끝까지는 정규분포에서 평균의 좌우 3표준편차 안에 측정된 관측치 양과 유사하다는 것을 알 수 있다.
'KHUDA' 카테고리의 다른 글
| KHUDA Data buisenss 02 (0) | 2024.03.20 |
|---|---|
| KHUDA Data buiseness 01 practice (3) | 2024.03.18 |
| KHUDA ML 세션 5주차 (1) | 2024.02.27 |
| KHUDA ML 세션 4주차 (1) | 2024.02.20 |
| KHUDA ML세션 3주차 (1) | 2024.02.13 |



