chapter 12 통계 기반 분석 방법론
분석 모델 개요
방법론은 크게 기계학습, 통계모델 두가지로 나누어 진다.
통계 모델
모형과 해석을 중요하게 생각하며, 오차와 불확정성을 강조한다.
기계 학습
대용량 데이터를 활용하여 예측의 정확도를 높이는 것을 중요하게 생각한다 .
기계 학습도 통계 모델의 원리를 기본으로 하고있다.

기계 학습 데이터 분석 방법론은 크게 지도학습과 비지도 학습(강화학습)으로 구분할 수 있다.
또 독립변수와 종속변수의 속성에 따라 방법론이 결정된다. 질적 척도인지, 양적척도인지에 따라 분석 방법론이 달라진다.
하나의 방법론이 양적, 질적 변수 형태 모두 사용가능한 경우도 있다.

지도학습은 입력에 대한 정답이 주어져 결과와 정답사이의 오차가 줄어들도록 학습과 모델수정을 반복한다.
- 결과값이 양적 척도이면 회귀방식의 방법론
- 결과값이 질적 척도이면 분류방식의 방법론
비지도학습은 별도의 정답이 없이 변수 간의 패턴을 파악하거나 데이터를 군집화하는 방법이다.
- 차원 축소는 지도학습을 할때 성능을 높이기 위한 전처리 방법
- 군집분석은 정답지(labeling) 없이 유사한 관측치끼리 군집으로 분류하는 기법
- 연관규칙분석(assicuating rules)은 연관성을 수치화하여, 소비자가 앞으로 구매할 가능성이 높은 제품을 추천하도록 할 수 있는 방법론
강화학습은 동물이 시행착오를 통해 학습하는 과정을 콘셉으로 한 방법중 하나이다.
ex) 원숭이에게 충격이 오는 a버튼과 바나나가 떨어지는 b 버튼을 두었을때 나중으로 갈 수록 원숭이는 a버튼만 누른다.
Chapter 12.1 주성분 분석(PCA)
주성분 분석(PCA)
여러 개의 독립변수들을 잘 설명해주 수 있는 주된 성분을 추출하는 기법이다.
핵심 특성만 선별하기 때문에, 독립변수(차원)수를 줄일 수 있다.
변수의 수를 줄임으로써 모형을 간단하게 만들 수 있고 분석 결과를 보다 효과적으로 해석할 수 있다.
주성분 분석에 사용되는 변수는 모두 등간 척도나 비율척도로 측정한 양적변수여야 하고 관측치들이 서로 독립적이고 정규분포를 이루고 있어야 한다.
차원 감소 방법
- 변수 선택을 통해 비교적 불필요하거나 유의성이 낮은 변수를 재거하는 방법
- 변수들의 잠재적인 성분을 추출하여 차원을 줄이는 방법
주성분 분석은 변수의 수를 축약하면서 정보의 손실을 최소화 하고자 할때 사용된다.
다차원의 데이터 분포 속에서 위치하는 점들의 분산을 최대한 보존하는 축을 통해 차원을 축소하는 것이 핵심 요소이다.
일반적으로 제1주성분, 제2주성분만으로 대부분의 설명력이 포함되기 때문에 두 개의 주성분만 선정한다.


2번 축보다 3번축이 가장 많은 분산을 담아낼 수 있어서 3번축이 주성분이 되는 것 이다.

3번축과 직교하는 선이 제2주성분이다. 3번축과 대비되게 짧은길이로 형성된다.
예시는 2차원이기 때문에 최대 2개의 주성분을 만들 수 있다. 만약 변수가 10개라면 총 10개의 주성분을 만들 수 있다.
주성분 실습

array([0.454, 0.18 , 0.126, 0.098, 0.069, 0.042, 0.026, 0.004, 0. ])
c1은 45.4%, c2는 18% c3는 12.6% ...


c1,c2를 x,y축으로 하여 종속변수인 type가 어떻게 분포하는지 확인.

Chapter 12.3 공통요인분석(CFA)
PCA와 CFA는 요인분석을 하기 위한 기법의 한 종류이다.
요인분석은 말 그대로 주어진 데이터의 요인을 분석한다는 큰 개념이고, 요인분석을 하기 위해 전체 분산을 토대로 요인을 추출하는 PCA를 사용하거나 공통분산만을 토대로 요인을 추출하는 CFA를 선택할 수 있다.
확인적 요인분석(CFA)
이미 변수들의 속성을 예상하고 있는 상태에서 실제로 구조가 그러한지 확인하기 위한 목적으로 쓰임
공통요인분석(CFA)
전체 독립변수를 축약한다는 점에서 PCA와 동일하지만, 상관성이 높은 변수들을 묶어 잠재된 몇 개의 변수를 찾는다는 점에서 차이가 있다. 정확성 관점에서는 CFA가 PCA보다 우수한 면이 있다.
CFA로 생성한 주성분들은 서로 간에 무엇이 더 중요한 변수라는 우위개념이 없다 .
종속변수에 대한 설명력 차이는 있겠지만, 기본적으로 종류가 다른 변수를 만들어내는 것이 목적이다.
요인분석을 하기 위해서는 우선 독립변수들 간의 상관성이 요인분석에 적합한지 검증을 해야한다.
- Bartlett test : 행렬식을 이용하여 카이제곱값을 구하여 각 변수 사이의 상관계수의 적합성을 검증
- KMO 검정 : 변수들 간의 상관관계가 다른 변수에 의해 잘 설명되는 정도를 나타내는 값을 통계적으로 산출하는 검정방법
적합성을 검증한 후에는 요인 분석을 통해 생성되는 주성분 변수들의 고유치를 확인하여 요인의 개수를 결정한다.
(고유치는 요인이 설명해주는 분산의 양을 뜻하는 함)
요인에 해당하는 변수들의 요인 적재 값의 제곱 합 값들을 합하여 구할 수 있다.

엘보우 포인트(elbow point)
직관적으로 고유치를 확인할 수 있으며 그래프의 경사가 낮아지는 지점을 통해 적정요인을 선정하는데 참고

요인 적재 값을 통해 각 변수와 요인 간의 상관관계의 정도를 확인할 수 있다. 선정된 각 요인이 어떤 변수를 설명해 주는가를 나타낸 것이다.
공통요인분석 실습
적합성을 검증하기 위해 바틀렛 테스트를 수행한다. 아웃풋 결과의 p-value 가 0.0으로 출력됐기 때문에 공통요인분석을 하기에 적합한 것을 알 수 있다.
0.700895049557787
변수 그룹간의 상관관계가 각각 다르게 나뉘는지 확인하기 위해 KMO 검정을 수행한다. 앞에서 다뤘듯이 0.7은 '약간 높음' 수준이므로 준수한 수준

4개 요인 지점 이후 경사가 급격히 감소하기에 4개의 요인을 선정하는 것이 적절한 것으로 판단된다.

단순한 테이블 형태는 요인별로 주요 변수를 확인하기 어렵기 때문에 시각화를 한다.
주의할 점은 +=1에 가까운지 표현해야 하기 때문에 abs 함수를 적용하여 절댓값으로 시각화가 표현되도록 해야한다.
Chapter 12.4 다중공선성 해결과 섀플리 밸류 분석
다중공산성(multicollinearity)
독립변수들 간의 상관관계가 높은 현상을 뜻한다. 즉 두 개이상의 독립변수가 서로 선형적인 관계를 나타낼 때 다중공산성이 있다고 말한다. 독립 변수들 간에 서로 독립이라는 회귀 분석의 전제 가정을 위반하게 된다. 회귀 모델은 첫 번째 독립 변수가 종속 변수를 예측하고 두 번째 독립 변수가 남은 변량을 예측하는 식으로 구성된다. 그런데 다중 공산성이 있는 경우 두 변수가 설명할 수 있는 부분이 거의 동일하므로 두 번째 변수가 설명할 수 있는 변량이 거의 없게 된다.
판별 기준
- 회귀 분석 모델을 실행하기 전에 상관 분석을 통해 독립 변수 간의 상관성을 확인하여 높은 상관계수를 갖는 독립변수를 찾아내는 방법. 상관계수의 절대치가 0.7 이상이면 두 변수 간의 상관성이 높다는 것으로 다중 공산성이 나타날 것을 의심할 수 있다. 다만 변수가 많을 경우 상관성 파악 어려움.
- 회귀 분석 결과에서 독립 변수들의 설명력을 의미하는 결정계수 R^2 값은 크지만 회귀계수에 대한 t값이 낮다면 다중공산성을 의심해 볼 수 있다. 종속변수에 대한 독립 변수들의 설명력은 높지만 각 계수 추정치의 표준 오차가 크다는 것은 독립 변수 간에 상관성이 크다는 것을 의미하기 때문이다.
- VIF(Variance Inflation Factor), 분산 팽창계수를 통해 다중공산성을 판단할 수 있다. 해당 변수의 VIF 값은 회귀분석 모델에 사용된 다른 독립 변수들이 해당 변수 대신 모델을 설명해 줄 수 있는 정도를 나타낸다. VIF가 크다는 것은 해당 변수가 다른 변수들과 상관성이 높다는 것이기 때문에 회귀 계수에 대한 분산을 증가시키므로 제거해주는 것이 좋다.
- 주성분 분석을 통해서도 해결 가능하다. 하지만 변수의 해석이 어려워진다.
- 데이터 분석 환경에서 제공하는 변수 선택 알고리즘 활용 방법이 있다. 전진 선택법(Forward selection), 후진 제거법(Backward elimination), 단계적 선택법(Stepwise method)중 하나를 선택하여 특정 로직에 의해 모형에 적합한 변수를 자동으로 선정한다.
섀플리 밸류(Shapley Value)
각 독립변수가 종속변수의 설명력에 기여하는 순수한 수치를 계산하는 방법.
Chapter 12.5 데이터 마사지와 블라인드 분석
데이터 마사지
데이터 분석 결과가 예상하거나 의도한 방향과 다를 때 데이터의 배열을 수정하거나 관점을 바꾸는 등 동일한 데이터라도해석이 달라질 수 있도록 유도하는 것. 분석가의 주관적 판단이 개입되기 때문에 지양해야 한다.
데이터 마사지 방법
- 편향된 데이터전처리: 이상치나 결측값 등의 전처리를 분석가가 의도하는 방향에 유리하도록 하는 것. 이상치나 결측값을 의도한 방향에 유리하도록처리하는 것.
- 매직그래프 사용: 그래프의 레이블 간격이나 비율을 왜곡하여 수치의 차이를 실제보다 크거나 작게 인식하도록 유도하는 방법. 데이터 조작과 다름없는 방법이기 때문에 절대 사용해서는 안 되며 매직그래프에 속지 않도록 주의해야한다.
- 분모 바꾸기 등 관점 변환: 동일한 비율 차이라 하더라도 분모를 어떻게 설정하는가에 따라 받아들여지는 느낌이 달라질 수 있다.
- 의도적인 데이터 누락 및 가공: 데이터 분석가가 원하는 방향과 반대되는 데이터를 의도적으로 누락시키거나 다른 수치와 결합하여 특성을 완화시키는 방법이다.
- 머신러닝 모델의 파라미터 값 변경 및 연산 반복: 통계적 수치뿐만 아니라 머신러닝 모델의 결괏값도 어느정도 유도가 가능하다. 모델의 파라미터 값을 변경해 가며 다양하게 연산을 반복하다 보면 결과가 원하는대로 조정될 수 있다.
- 심슨의 역설: 데이터의 세부 비중에 따라 전체 대표 확률이 왜곡되는 현상을 의도적으로 적용하여 통계 수치를 실제와는 정 반대로 표현할 수 있다.
블라인드 분석
데이터 마사지에 의한 왜곡을 방지하기 위해 사용하는 방법.
분석가의 주관적 판단이 개입되는 인지적 편향, 확증 편향을에 의한 오류를 최소화하기 위해 사용한다.
모든 것을 해결해주지는 못 한다. 편향을 완벽히 방지할 수 잇는 것도 아니고, 오히려 의미 없는 결과를 도출하게 될 수도 있다.
기존에 분석가가 중요하다고 생각했던 변수가 큰 의미가 없는 것으로 결과가 나왔을 때 무리해서 의미부여를 하거나 그 변수에 집착하여 해석에 유리하도록 변수를 가공하게 되는 실수를 방지하는 목적이 크다.
Chapter 12.6 Z-test 와 T-test
Z-test와 T-test는 단일 표본 집단의 평균 변화를 분석하거나 두 집단의 평균값 혹은 비율 차이를 분석할 때 사용한다. 분석하고자 하는 변수가 양적 변수이며, 정규 분포이고, 등분산이라는 조건이 충족되어야 한다. 두 분석 방법을 선택하는 기준은 모집단의 분산을 알 수 있는지의 여부와 표본의 크기에 따라 달라진다.
T-test
평균의 차이가 클수록, 표본의 수가 클수록 t값은 증가하게 된다. 반대로 관측치들의 값 간의 표준편차가 크면 평균의 차이가 불분명해지게 되고 t값은 감소한다.

Z-test

Chapter 12.7 ANOVA(Analysis of Variance)
ANOVA(Analysis of Variance)
세 집단 이상의 평균을 검정할 때 사용한다. T-test에서 A,B검정, B,C검정, C,A검정하면 되지만 중복하여 검정을 하면 신뢰도가 하락하는 문제가 발생한다. 분산 분석이라고도 많이 불리는데 T분포를 사용하는 T-test와 달리 F분포를 사용한다. F분포는 집단간의 분산의 비율을 나타낸다.

항상 양의 값을 가지며 오른쪽으로 긴 꼬리 형태를 보인다. 독립변수가 종속변수에 미치는 영향을 분석한다.
독립변수인 요인의 수에 따라서 다르게 불린다. 독립변수는 집단을 나타낼 수 있는 범주(분류)형 변수이어야 하며, 종속 변수는 연속형 변수이어야 한다. 독립변수와 종속변수의 형태에 따라 회귀분석이나 교차분석으로 분석 방법이 바뀐다.
ANOVA는 각 집단의 평균값 차이가 통계적으로 유의한지 검증한다. 집단 내의 각 관측치들이 집단 평균으로부터 얼마나 퍼져 있는지를 나타내는 분산, 즉 집단 내 분산이 사용되며 전체 집단의 통합 평균과 각 집단의 평균값이 얼마나 퍼져 있는지를 나타내는 집단 간 평균의 분산이 사용된다.

chapter 12.8 카이제곱 검정(교차 분석)
카이제곱 검정
교차분석(Crosstabs)이라고도 불리며, 명목 혹은 서열척도와 같은 범주형 변수들 간의 연관성을 분석하기 위해 결합 분포를 활용하는 방법. ‘연령’과 같은 비율척도 변수는 ‘연령대’와 같은 서열척도로 변환해서 사용해야 한다. 기본 원리는 변수들 간의 범주를 동시에 교차하는 교차표를 만들어 각각의 빈도와 비율을 통해 변수 상호 간의 독립성과 관련성을 분석하는 것이다. 교차 분석은 상관 분석과 달리 연관성의 정도를 수치로 표현할 수 없고 검정 통계량 카이 제곱을 통해 편수 간에 연관성이 없다는 귀무가설을 기각하는지 여부로 상관성을 판단한다.
카이제곱 검정 실습

Chi square: 7.8081404703715105 P-value: 0.005201139711454792
Chapter 13.1 선형 회귀분석과 Elastic Net(예측모델)
회귀분석
결국 각 X(독립변수)의 평균을 통해 Y(종속변수)를 예측한다. 회귀분석은 독립변수가 종속변소에 주는 영향력을 제외한 변화량인 오차항을 최소화하는 절편과 기울기를 구하는 것이다.
최소제곱추정법
최적의 회귀선을 구하는 것은 “모형 적합”이라 부르며 회귀선과 각 관측치를 뜻하는 점간의 거리를 최소화하는 것이다. 예측치와 관측치들 간의 수직 거리(오차)의 제곱합을 최소로 하는 직선이 회귀선이 된다.
- 단순 회귀분석(Simple regression analysis)혹은 단변량 회귀분석 : 독립변수가 하나
- 다중 회귀 분석(Multiple regression analysis)혹은 다변량 회귀분석 : 독립변수가 두개 이상
독립변수와 종속변수가 비선형적 관계일 경우 예측력이 떨어지는 문제가 발생한다. ex. 향수 더 뿌릴수록 매력도 향상하다가 일정 수준 이상이 되면 매력도가 떨어짐.
이런 비선형적인 관계를 회귀분석 하기 위해 변수를 구간화해 이항변수로 표시된 몇 개의 더미변수로 변환하여 분석하면 된다.
다항회귀(Polynomial regression)
다항회귀란 독립변수와 종속변수의 관계가 비선형 관계일 때 변수에 각 특성의 제곱을 추가하여 회귀선을 비선형으로 변환하는 모델이다. 차수가 커질수록 평향은 감소하지만 변동성이 증가해 분산이 늘어나고 과적합을 유발할 수 있다.

다중공산성을 판단할 수 있는 Tolerance와 VIF는 공차한계와 분산팽창지수를 뜻한다. 변수의 조합에 따라 유의도와 공선성 통계량의 변화 때문에 변수 선정이 까다롭다. 분석가가 수동으로 일일이 변수 조합을 테스트 하는 것은 비효율적이기 때문에 자동으로 조합을 선택할 수 있는 세 가지 변수 선택 알고리즘을 살펴볼 것이다.
- 전진 선택법(Forward Selection): 단순한 변수 선택법으로, 절편(Intercept)만 있는 모델에서 시작하여 유의미한 독립변수 순으로 변수를 차례로 하나씩 추가하는 방법이다. 빠르다는 장점이 있지만 한 번 선택된 변수는 다시 제거되지 않는다.
- 후진 제거법(Backward Elimination): 모든 독립변수가 포함된 상태에서 시작하여 유의미하지 않는 순으로 설명변수를 하나씩 제거하는 방법이다. 학습 초기에 모든 변수를 넣고 모델 학습을 하기 때문에 시간이 다소 오래 거릴 수 있지만 유의미한 변수를 처음부터 모두 넣고 시작하기 때문에 전진선택법보다는 안전한 방법이다.
- 단계적 선택법(Stepwise Selection): 전진 선택법과 후진 제거법의 장점을 더한 방법이다. 처음에는 전진 선택법과 같이 변수를 하나씩 추가하기 시작하면서, 선택된 변수가 3개 이상이 되면 변수 추가와 제거를 번갈아 가며 수행한다. 최적의 변수 조합을 찾아낼 가능성이 높지만 시간이 오래 걸린다.
그 밖에 선택법 알고리즘을 개선한 LARS(Least Angle Regression), 변수의 조합에 약간의 우연적 요소를 가미한 변화를 주어 기존 변수 조합과는 다른 새로운 변수의 조합을 탐색할 수 있는 유전 알고리즘 등이 있다. 하지만 최근엔 변수 계수에 가중치를 주어 편향을 허용함으로써 예측 정밀도(prediction precision)를 향상시킬 수 있는 Ridge와 Lasso를 조합한 Elastic Net을 사용하는 경우가 많다.
Ridge, Lasso
Lasso는 Ridge와 유사하지만, 중요한 몇 개의 변수만 선택하고 나머지 변수들은 계수를 0으로 주어 변수의 영향력을 아예 없앤다는 차이가 있다.
Elastic Net
Ridge와 Lasso의 최적화 지점이 다르기 때문에 두 정규화 항을 결합하여 절충한 모델이다. Ridge는 변환된 계수가 0이 될 수 없지만 Lasso는 0이 될 수 있다는 특성을 결합한 것이다. 혼합비율 r을 조절하여 모델의 성능을 최적으로 끌어낸다.
Chapter 13.2 로지스틱 회귀분석( 분류 모델)
로지스틱 회귀분석(Logistic Regression)
선형회귀분석과 유사하지만 종속변수가 양적척도가 아닌 질적척도라는 차이가 있다. 즉, 특성 수치를 예측하는 것이 아니라 어떤 카테고리에 들어갈지 분류를 하는 모델이다. 기본 모형은 0,1 이항으로 이루어져 예측하고, 종속변수의 범주가 3개 이상일 경우 다항 로지스틱 회귀분석(Multinominal Logistic Regression)을 통해 분류 예측을 할 수 있다.

로짓 회귀선으로 변환해주기 위해 오즈 값을 구해야 한다. 오즈 값에 로그를 취한 뒤 로짓 변환하여 0에서 1 사이로 치환해줘야 한다. 이를 시그모이드 함수라고 한다.
다항 로지스틱 회귀분석은 종속변수의 모든 범주에 해당하는 확률의 합을 100%로 한다. 이항 로지스틱 식이 K-1개가 필요하다.
선형 회귀분석 모형 결과와 차이가 있다면 각 변수의 오즈비를 알 수 있다는 것이다. 로지스틱 회귀분석도 R^2값이 산출 되는데 알려진 방법만 10가지가 넘는다. 하지만 로지스틱 회귀분석과 같은 분류 모델은 이러한 측정 값보다 Test data set에서 실제로 얼마나 올바르게 분류했는가를 따져서 모델의 성능을 평가하는 것이 좋다.
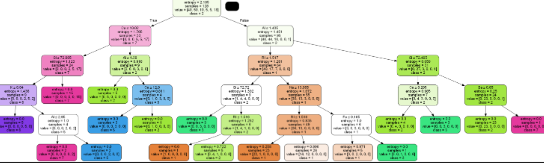
chapter 13.3 의사결정나무와 랜덤 포레스트(예측/분류 모델)
분류나무와 회귀나무
명목형의 종속변수를 분류할 수 있는 분류나무와 연속형의 수를 예측할 수 있는 회귀나무가 있다. 두 모델 모두 양적 척도와 질적 척도의 독립변수를 다 사용할 수 있다.

가장 잘 나눠줄 수 있는 기준은 불순도(Impurity)를 낮추고 순도(Homogeneity)를 높이는 방향으로 분류 기준을 찾아낸다. 한 노드 내에서는 범주의 동질성이 최대한 높고, 노드 간에는 이질성이 최대한 높도록 만들어 주는 것이다. 데이터 불순도를 나타내는 대표적인 기준이 지니계수(Gini index)와 엔트로피(Entropy)다. 분류를 통해 지니계수나 엔트로피가 증가/감소한 양을 정보 획득량(Information gain)이라 한다.
지니 계수는 최대치가 0.5, 하나의 범주로만 이루어진 순수한 데이터일 경우 0이 된다.
엔트로피는 지니 계수와 비슷하지만 이진로그를 취함으로써 정규화 과정을 거치게 된다. 값의 범위는 0~1을 갖게 된다.
회귀나무
종속변수가 연속형 변수이기 때문에 지니계수나 엔트로피 대신 진차 제곱합(Residual Sum of Square, RSS)등의 분류 기준을 사용한다.
회귀나무는 끝 노드에 속한 데이터 값의 평균을 구해 회귀 예측값을 계산한다. F-value나 분산의 감소량을 분류 기준으로 사용한다. F-value가 크다는 것은 노드 간의 이질성이 높다는 것을 의미하느로 F-value가 최대한 커지는 방향으로 자식 노드를 나눈다. 분산의 감소량의 경우, 한 노드에 속한 관측치 값들의 분산이 작아진다는 것은 동질성이 높다는 것을 의미하므로 노드의 분산이 최소화되도록 자식 노드를 나누는 것이다.
랜덤 포레스트
이러한 보정을 하더라도 학습 성능의 변동이 크다는 고질적인 문제가 있기 때문에 나온 모델이 랜덤포레스트이다. 나무를 여러개 만들어 학습하게 되면 다양한 상황을 고려하여 학습이 되기 때문에 과적합을 방지할 수 있다. 집단지성과 같은 개념으로, 앙상블 학습(Ensemble learning)이라고도 한다.

부트스트랩(Bootstrap)과 배깅(Bagging)
부트스트랩은 하나의 데이터셋을 중복을 허용하여 무작위로 여러 번 추출하는 것이다. 신뢰구간에 대한 통계적 추정의 정확도를 높이는 데 사용하는 유용한 방법이다. 무작위로 선택할 독립변수의 수는 특별히 정해진 규칙은 없지만 일반적으로 전체 독립변수 개수의 제곱근으로 한다.
배깅은 Bootstrap aggregating의 약자로 여러 개의 의사결정 나무를 하나의 모델로 결합해 주는 것이다. 투표방식(Voting)으로 집계하며 연속형 값의 예측 모델인 경우 평균(Average)으로 집계한다. 이와 유사한 개념으로 부스팅이 있다. 부스팅은 각 트리모델을 순차적으로 학습하며 정답과 오답에 가중치를 부여해 준다는 차이가 있다. 따라서 보다 정밀한 예측이 가능하지만, 역시 과적합의 위험이 높으며 이상치에 취약하다는 단점이 있다.
0.686046511627907

'KHUDA' 카테고리의 다른 글
| KHUDA Data Business 05 (1) | 2024.04.14 |
|---|---|
| KHUDA Data business 04 (0) | 2024.04.03 |
| KHUDA Data business 02 practice (1) | 2024.03.26 |
| KHUDA Data business 02 심화발제 (0) | 2024.03.20 |
| KHUDA Data buisenss 02 (0) | 2024.03.20 |



